Sample Size Re-estimation (SSR)
Overview
In summary:
- SSR offers researchers an opportunity to appropriately change the sample size they originally planned when designing the trial;
- Researchers need to specify in advance: the design parameters to re-estimate during the trial; how these parameters are re-estimated and when; how the sample size is then re-calculated and; the decision rules for changing the sample size;
- At each interim analysis, design parameters are re-estimated, initial assumptions made about them updated, and the sample size changed accordingly;
- SSR is useful when there is considerable uncertainty around design parameters before the trial begins;
- SSR methods considered here assume that the targeted treatment effect is fixed at the onset.
TO ADD VIDEO HERE
Motivation
In every clinical trial, researchers decide at the design stage (before the trial begins) the required sample size to reliably answer the research question(s). This might be the number of patients, or number of events for time-to-event outcomes (where not for every patient an event, such as death, is observed during the trial follow-up period). Calculating this sample size can be challenging (see 1). Recruiting more patients than necessary wastes resources, unnecessarily delays study results and thereby hinders quick decision-making, and may expose more patients to potentially unsafe study treatments.
On the other hand, researchers may not be able to answer the intended research question(s) if they fail to recruit an adequate sample size. For example, the chance of finding effective study treatments if they exist (statistical power) may be inappropriately low, the chance of falsely claiming evidence of benefit (type I error rate) may be inappropriately high, or the trial may produce equivocal results. Furthermore, a sizable proportion of trials require a funding extension due to recruitment challenges 2, 3, 4. Some of these trials might have been designed with unnecessarily large sample sizes in the first place – so they may not need a funding extension request at all. All these issues raise scientific, ethical, economic, and feasibility questions.
On the other hand, researchers may not be able to answer the intended research question(s) if they fail to recruit an adequate sample size. For example, the chance of finding effective study treatments if they exist (statistical power) may be inappropriately low, the chance of falsely claiming evidence of benefit (type I error rate) may be inappropriately high, or the trial may produce equivocal results. Furthermore, a sizable proportion of trials require a funding extension due to recruitment challenges 2, 3, 4. Some of these trials might have been designed with unnecessarily large sample sizes in the first place – so they may not need a funding extension request at all. All these issues raise scientific, ethical, economic, and feasibility questions.
At the design stage, researchers need to make assumptions about specific design parameters that are used to estimate the sample size. The most commonly used design parameter is the variability of the primary outcome. In some cases, published or unpublished data from related studies may exist to inform these assumptions. In other cases, assumptions are based on the opinions of researchers when prior data is unavailable. Considerable uncertainties may exist around these estimates. PANDA users may wish to read introductory material on “what is an adaptive design”.
Assumptions on design parameters may be uncertain because of several factors including:
- failure to adequately review evidence from prior studies;
- limited availability of prior data;
- overoptimistic opinions of researchers;
- retrofitting by researchers to make the study feasible (e.g., tweaking design parameters to give a practically achievable sample size);
- differences in the settings of prior and current studies;
- differences in patient characteristics in prior studies and the targeted study group;
- differences in how outcomes are assessed and when they are assessed in prior studies;
- improvements in patient care in the comparator arm since previous studies took place.
In context
Several researchers have reported marked discrepancies between estimates of design parameters assumed at the design stage and those observed on trial completion 5, 6, 7, 8. Reviews found that only 73 (34%) of trials made accurate assumptions about the control event rate where it differed by less than 30% of the observed event rate 5, 24 (80%) of continuous outcomes had markedly greater variability than assumed 6, and 32 (80%) of rheumatoid arthritis trials recruited more patients than necessary 7. A review of protocols submitted to the UK research ethics committees found that trials tended to recruit more patients than necessary (i.e., they were “overpowered”) 8. Figure 1 illustrates the magnitude of discrepancy between the assumed (green line) and observed control event rate (red dashed line) from the RATPAC trial 9 as patients were recruited sequentially. The observed control event rate was always below the anticipated 0.5 (conservative rate assumed before the trial began). The entire trial duration is displayed only for illustration purposes.
Figure 1.
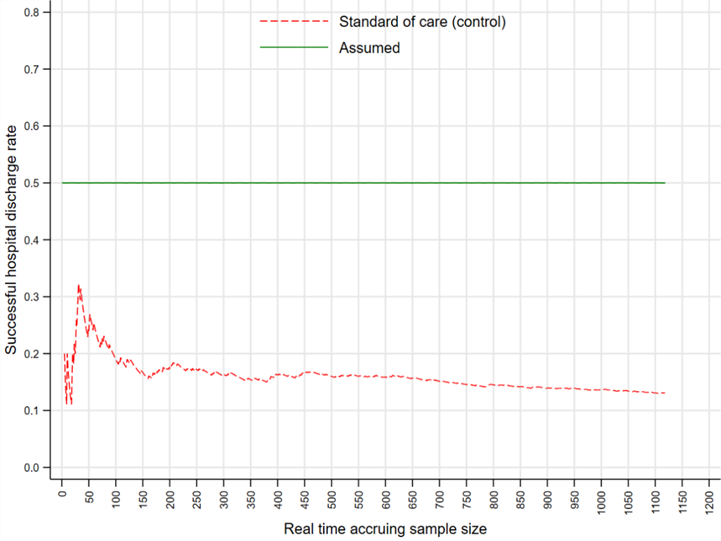
RATPAC sequential hospital discharge rate.
In summary
Uncertainties around design parameters exist in every trial; however, the magnitude of uncertainties and their implications on the operating characteristics of the design (e.g., achieved power) vary from trial to trial.
The goal of sample size re-estimation (SSR) is to update assumptions around design parameters and change the original sample size appropriately based on interim data from a group of patients already recruited into the trial. Thus, researchers can achieve the desired statistical power while avoiding over- or under-recruitment of patients, both of which are associated with inefficient and/or wasteful use of research resources.
The goal of sample size re-estimation (SSR) is to update assumptions around design parameters and change the original sample size appropriately based on interim data from a group of patients already recruited into the trial. Thus, researchers can achieve the desired statistical power while avoiding over- or under-recruitment of patients, both of which are associated with inefficient and/or wasteful use of research resources.
References
1. Fayers et al. Sample size calculation for clinical trials: The impact of clinician beliefs. Br J Cancer. 2000;82(1):213–9.
2. Sully et al. A reinvestigation of recruitment to randomised, controlled, multicenter trials: a review of trials funded by two UK funding agencies. Trials. 2013;14(1):166.
3. McDonald et al. What influences recruitment to randomised controlled trials? A review of trials funded by two UK funding agencies. Trials. 2006;7(1):9.
4. Pemberton et al. Performance and predictors of recruitment success in National Heart, Lung, and Blood Institute’s cardiovascular clinical trials. Clin Trials. 2018;15(5): 444-451.
5. Charles et al. Reporting of sample size calculation in randomised controlled trials: review. BMJ. 2009;338(may12_1):b1732.
2. Sully et al. A reinvestigation of recruitment to randomised, controlled, multicenter trials: a review of trials funded by two UK funding agencies. Trials. 2013;14(1):166.
3. McDonald et al. What influences recruitment to randomised controlled trials? A review of trials funded by two UK funding agencies. Trials. 2006;7(1):9.
4. Pemberton et al. Performance and predictors of recruitment success in National Heart, Lung, and Blood Institute’s cardiovascular clinical trials. Clin Trials. 2018;15(5): 444-451.
5. Charles et al. Reporting of sample size calculation in randomised controlled trials: review. BMJ. 2009;338(may12_1):b1732.
6. Vickers. Underpowering in randomized trials reporting a sample size calculation. J Clin Epidemiol. 2003;56(8):717–20.
7. Celik et al. Are sample sizes of randomized clinical trials in rheumatoid arthritis too large? Eur J Clin Invest. 2014;44(11):1034–44. Available from:
8. Clark et al. Sample size determinations in original research protocols for randomised clinical trials submitted to UK research ethics committees: review. BMJ. 2013;346(mar21_1):f1135.
8. Clark et al. Sample size determinations in original research protocols for randomised clinical trials submitted to UK research ethics committees: review. BMJ. 2013;346(mar21_1):f1135.
9. Goodacre et al. The RATPAC (Randomised Assessment of Treatment using Panel Assay of Cardiac markers) trial: a randomised controlled trial of point-of-care cardiac markers in the emergency department. Health Technol Assess. 2011;15(23).